tl;dr this article presents an arbitrary evaluation of the different commonly available image recognitions services. The key takeaway of this would be to use Clarifai, if you look for best labeling, and Microsoft if false positives are something you would like to avoid as much as you can. Google or then Amazon are representing a good trade-off. You can jump to the first result graph presented sums up the global performance of each service.
Baby, this is 2017! If you are not using deep learning to guess your next commit message you are probably not as artificial intelligence as you should be.
I am pretty much trying to avoid the buzzword fudge usually served every time you write software that is supposed to be smart in some sense. Nevertheless last december I was assisting a project where, suddenly, using image recognition was making sense.
Basically we were crawling content from different websites and one of the key problems to make this scale properly was to get a better classification. The challenge was to take content from different websites and sort it into our own categories tree. The provided data about an item was:
- Url
- Name
- Description
- Pictures
For some, the description was not enough, even for a human to classify correctly. Though most pictures were usually unambiguous and pretty easy to identify for the human eye, a proper image recognition would simplify this classification problem to a simple remapping from the labels detected to the categories we hope. A much simpler problem as it could be easily solved with a satisfying precision by a human made decision tree.
We ended up using Amazon Rekognition for this specific need, as all of our infrastructure was already running inside AWS. This was the most easy to integrate and as time and keeping system complexity low were two important constraints, I mostly explored other options to know what possible enhancement is at hand.
Protocol
Usually services provide labels with a confidence, anything below 0.5 has been discarded and not considered.
When doing label detection there are two things that you are two different objectives:
- Getting the most precise labels for every elements of a picture, eventually labels could explore a semantic hierarchy, for example, a “dress” is a piece of “clothing”. This is close to counting true positives in a basic classification case.
- Avoiding wrong labels, what I called noise. This is close to counting false positives.
The analogy to true positives and false positives reaches its limit when you consider that an element could be counted in both set, you have right labels among erroneous ones.

For example, the above picture, could be labeled correctly: “field”, “people”, “moutain”, “pine tree” and “sky” ; and also incorrectly “cow” and “painting”.
On both dimensions I have arbitrarily scored the result from the tested service:
- 0: means worst outcome, missing labels or a lot of noise
- 5: means best outcome, right labels or very good signal noise ratio
It is fair to not consider minor differences as meaningful as per the subjective process of evaluation of the output provided by the different services.
Please note that those tests has been ran in late December 2016, except for Clarifai that I considered only in March 2017, services may have evolved since then, even though I did not notice changes while I played again with the first ones.
The datasets, the scoring and the graph generation is available on Github.
Services
I have tested the services of the three leaders in the industry of the cloud services: Amazon, Google and Microsoft, and one startup a friend recommended after reviewing a first version of this article: Clarifai.
Amazon Rekognition
Amazon Web Services is a defacto standard for many startups, their image recognition service is called Rekognition. It integrates like another AWS service, which means quite easily if you are able to get through the quite convoluted and abstruse documentation. Rekognition is part of the AWS Free Tier, so you can get started and play with it for free.
It can work directly from an S3 file identifier which might come handy if your data is already inside S3.
The biggest drawback for Rekognition is that you need an AWS account to be able to experiment with it and make some quick tests. It is not very outsider friendly, though if you have an AWS account a web interface lets you upload some image and get a result.
Google and Microsoft let you see how their product work on your data without the need to be a registered user.
Clarifai
Clarifai is dedicated to image recognition … and they seem to do it well. Aside what others do, they tend to extract high level concepts from pictures which could seriously ease content exploration.
For example an image with a good looking landscape would be labeled “travel”, one with a nice Desktop view “business” and a nicely dressed woman as “fashion”. They usually give back much more labels than the other services, but their recognition ability is the most impressive.
Google Cloud Vision API
Google offers perhaps the most elaborate service for image recognition with its Cloud Vision API, all services are offering to detect faces and facial expression but Google brings it to the next step.

I have discovered this awesome landmark recognition feature out of the blue, as it worked only for one of the dozen landscape pictures I tested. Google seems to be able to recognize where a picture has been taken. I think that Street View data offers an unchallenged data source to match a landscape picture to some precise geographical position.
The file containing no coordinates in its exif metadata, we still have to consider that Google may also have leveraged some data it has discovered while indexing this very picture from Unsplash. But this would be cheating and I consider it unlikely.
Microsoft Computer Vision API
Microsoft is the cloud reference for those working around the .NET stack, they have tried to develop things under a different approach than the two others, for example, their Machine Learning tool is more a web enabled modern competitor to what SAS offers through its outdated Entreprise Miner, than to what Amazon offers through an API.
The Computer Vision API is not extremely different from Amazon’s with the exception that you can easily play with it online and that the test interface is more pleasant to use.
Global performance
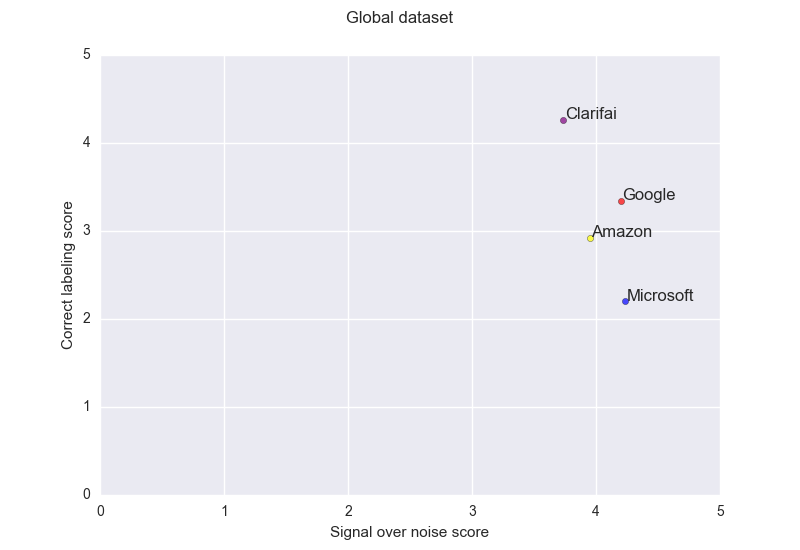
Basically we can see a Pareto curve where you can make your tradeoff between: precision and noise. Even though on many sets the Clarifai solution seems to just be dominating the others.
Datasets
Every dataset is composed of twenty images. For every dataset though I have tried to discard some images in order to provide more diversity with what I was testing.
Amateur
This dataset has been composed with the most random things that you can find online, even though I have been avoiding the ones loaded with text. Some has been found on Imgur, some others on a website proposing explicitly to open random images from the internet. Some of the images in this dataset are pretty normal, others are representing a challenge precisely because of the humor or creativity that compose their key message.
An example of an easy one:

Some examples of hard ones, where the point of art or humour is the ambiguity:


This gives the following result:
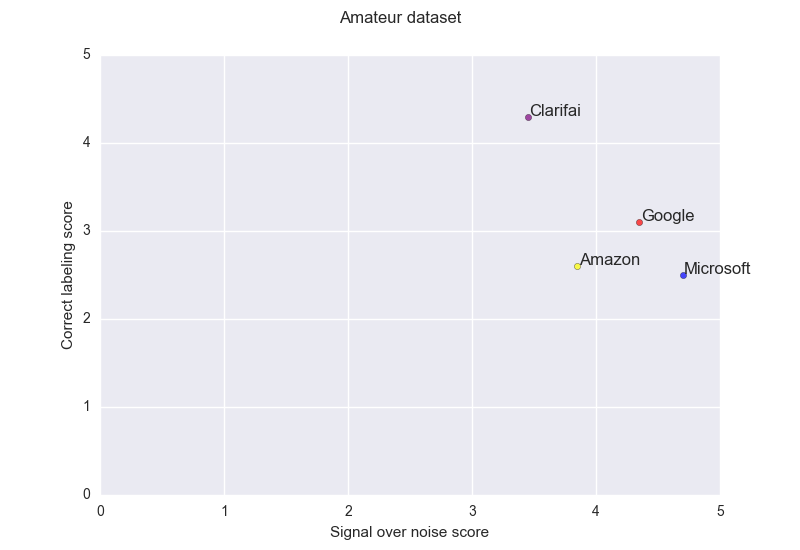
Clarifiai offers a different trade-off than the others and is quite impressive at analysis the content.
The three other services are offering similar performance, being in general only able to partially label the input.
Creative
The creative dataset is the most diverse in term of medium, its content comes from instagram (mine mostly), Fubiz, a leading creative media, and, Dribbble and DeviantArt, communities where creative can showcase their work. Pictures from weird angles, drawing or artistic compositions.



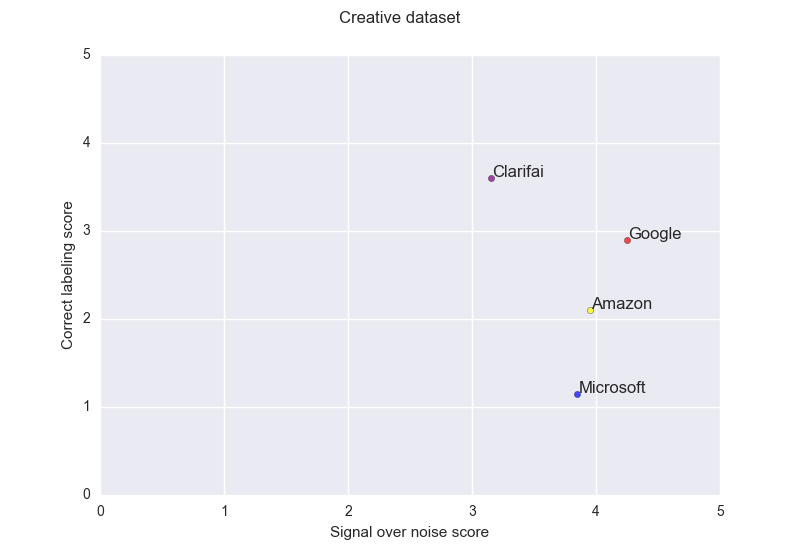
Definitely this dataset stretches the services to their limit, the ranking is clear for the three cloud services, Google then Amazon then Microsoft but none manage to achieve a correct labeling. As per the previous dataset Clarifai provides another trade-off.
Photography
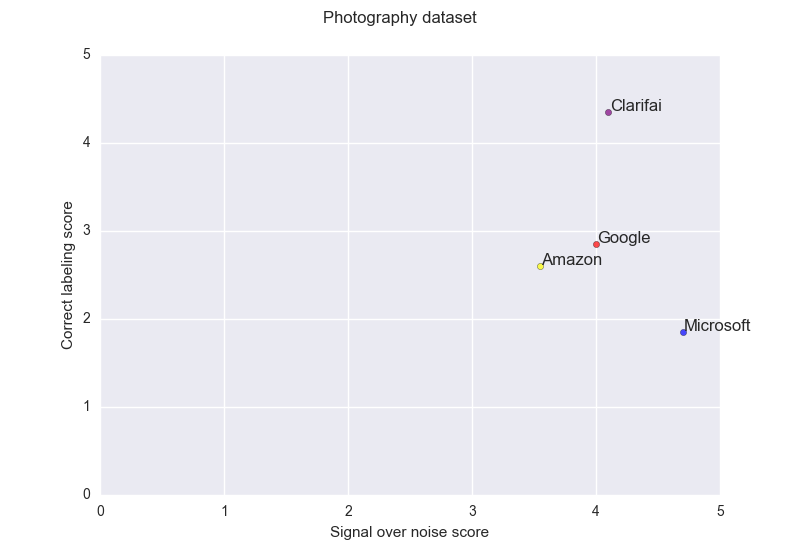
The photography dataset is perhaps the one fitting the most the user content upload use case. This one is perhaps lacking faces and portraits and still contains some kind of creative material. All pictures comes from unsplash.


Clarifia here dominates with no ambiguity the other services, Google and Amazon exhibit a similar behavior, Microsoft though is here the best choice to avoid noisy results in a compromise for correct labeling. This API has made the choice to rather give no answers rather than a possibly bad answer.
Products
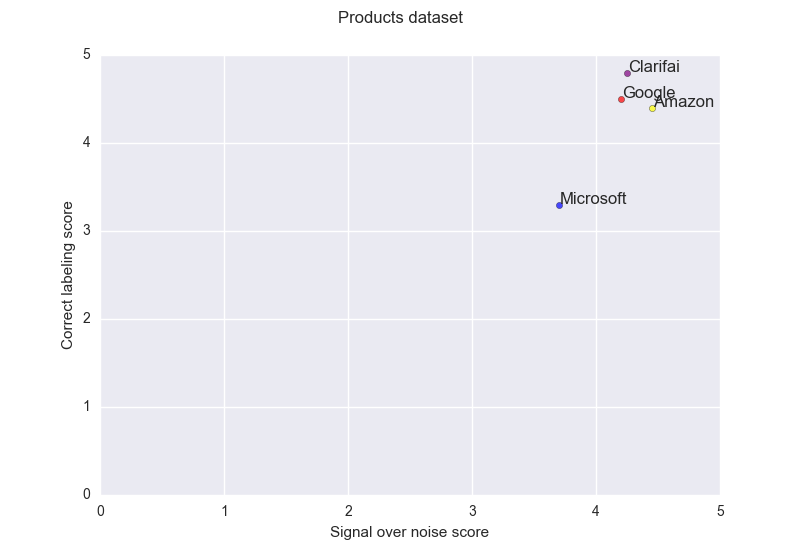
The products dataset is only composed with content from a promotion listing website. The products are supposedly the simplest thing to recognize, a single object on a white background.

On this dataset Amazon, Clarifai and Google provides extremely good performance with close to no error. Microsoft lags a bit behind.
Puritanism and the Specific Case of Porn
I initially thought about also benchmarking using a porn dataset. This dataset is in the form of a list of urls to be downloaded (as GitHub request no explicit content to be uploaded).
There is seems that there is failure by design. Those services are usually not only able to tell you “this is a bird”, they can tell you what species it is. They are better than most human beings at those tasks.
But when presented a woman in lingerie they give you the response of a confused father with a kid asking “what is this woman doing daddy?”, “well, she has her swimming costume on ; so she must be going to the beach”. If you want to launch yet another image recognition service, I suggest you to focus on this precise market where you most perhaps get close to no competition from those industry leaders.
A friend suggested that if you start to include adult terms, you venture into sketchy grounds when you get false positive. A flag to enable / disable adult labels could probably solve this problem.
Nevertheless, Microsoft and Google offers to identify if the content is adult or not with an appreciable accuracy.
Funnily, Microsoft presents a picture of a man swimming and one of a woman standing on the beach in their demo data. The man is not labeled as racy, the woman is. I would be curious to know how this has emerge: sheer experimental problem, manual labeling bias or bias extracted from some automated learning based generation from online content.
Conclusion
With a very similar pricing, the services performance can vary a lot, and depending on the requirements one service could predominate where another would fail, depending on the cost of noise and on the considered dataset.
In any case you mileage may vary a lot from one dataset to another, from close to perfect recognition to something partially or completely incorrect for 50% of the items.
